Scrapy整合selenium实现动态网络爬虫
这两天用scrapy和selenium写爬虫,踩了一些坑,现记录一下。
本文的重点主要介绍Scrapy架构和Scrapy框架爬取流程。
Scrapy
简介
Scrapy是一个快速的web爬虫框架,用于爬取网站并从页面中提取结构化的数据,可应用于数据挖掘、监测和自动化测试。
- 官网地址: https://scrapy.org/
- 用户手册: Scrapy documentation
架构
Scrapy架构如图所示:
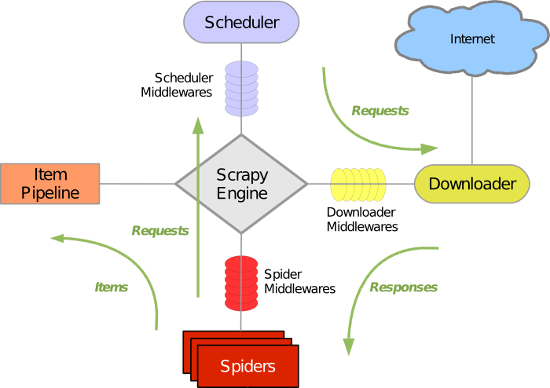
各组件说明
| 组件 | 作用 |
|---|---|
| Scrapy引擎(Scrapy Engine) | 用来控制整个系统的数据处理流程,并进行事务处理的触发。 |
| 调度器(Scheduler) | 用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。 |
| 下载器(Downloader) | 用于下载网页内容,并将网页内容返回给spiders。 |
| 爬虫(Spiders) | 用于分析response并提取item或额外跟进的URL的类. 每个spider负责处理一个特定(或一些)网站。 |
| 实体管道(Item Pipeline) | 负责处理爬虫从网页中爬取的实体,主要的功能就是持久化实体、验证实体的有效性、清除不需要的信息。 |
| 下载器中间件(Downloader Middlewares) | 位于scrapy引擎和下载器之间的框架,主要是处理scrapy引擎与下载器之间的请求及响应。设置代理ip和用户代理可以在这里设置。 |
| 爬虫中间件(Spider Middlewares) | 位于scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。 |
| 调度中间件(Scheduler Middlewares) | 位于scrapy引擎和调度器之间的框架,主要是处理从scrapy引擎发送到调度器的请求和响应。 |
执行流程
- 引擎从Spiders中获取到最初的要爬取的Requests
- 引擎安排Requests到调度器中,并向调度器请求下一个要爬取的Requests
- 调度器返回下一个要爬取的Requests给引擎
- 引擎将上步中得到的Requests通过Downloader Middlewares发送给下载器,这个过程中Downloader Middlewares中的process_request()函数会被调用到
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过Downloader Middlewares发送给引擎,这个过程中Downloader Middlewares中的process_response()函数会被调用到
- 引擎从下载器中得到上步中的Response并通过Spider Middlewares发送给Spider处理,这个过程中Spider Middlewares中的process_spider_input()函数会被调用到
- Spider处理Response并通过Spider Middlewares返回爬取到的Item及(跟进的)新的Request给引擎,这个过程中Spider Middlewares的process_spider_output()函数会被调用到
- 引擎将上步中Spider处理的其爬取到的Item给Item Pipeline,将Spider处理的Request发送给调度器,并向调度器请求可能存在的下一个要爬取的Requests
- 重复直到调度器中没有更多的Requests
安装与使用
pip install Scrapy # 安装Scrapy框架
scrapy startproject tutorial # 创建Scrapy项目
cd tutorial #进入项目文件夹
scrapy genspider example example.com #创建爬虫
scrapy crawl example # 运行爬虫
scrapy crawl example -o example.json # 运行爬虫并存储至文件中
文件结构
tutorial/
scrapy.cfg # 配置文件
tutorial/ # 项目文件夹
__init__.py
items.py # 实体定义文件
middlewares.py # 中间件文件
pipelines.py # 实体管道文件
settings.py # 项目配置文件
spiders/ # 存放spider文件
__init__.py
example.py # spider文件
各文件作用
| 文件名 | 作用 | 内容 |
|---|---|---|
| scrapy.cfg | 配置文件 | |
| items.py | 实体定义文件 | 需要抓取的item定义在这个文件内 |
| middlewares.py | 中间件文件 | 定义Downloader Middlewares,Spider Middlewares,比如调用selenium动态加载页面 |
| pipelines.py | 实体管道文件 | 执行持久化实体、验证实体的有效性、数据清洗等 |
| settings.py | 项目配置文件 | 配置默认请求头,代理等 |
| example.py | spider文件 | 对Response进行解析和提取 |
用户手册:Scrapy documentation
Selenium
简介
Selenium是一个浏览器模拟器,可用于web应用程序的自动化测试。
scrapy框架本身是个静态网页的爬虫框架,因此,在编写爬虫时可以与selenium相整合实现动态网页的爬取任务。使用selenium模拟浏览器请求,加载动态页面,提取结构化的数据。
安装
pip install selenium
# 使用不同的浏览器需下载对应的dirver
# 以chrome浏览器为例,还需下载chromedirver
# chromedirver仓库地址: http://chromedriver.storage.googleapis.com/index.html
# 将下载的chromedirver配置到环境变量中
使用
以下是一个最简单的示例。
from selenium import webdriver #导入库
browser = webdriver.Chrome() #声明浏览器
url = 'https:www.baidu.com'
browser.get(url) #打开网址
print(browser.page_source) #打印网页源代码
browser.close() #关闭浏览器
Selenium可以获取网页元素,模拟用户与浏览器交互等,详见用户手册。
用户手册: https://www.selenium.dev/documentation/en/
项目实战
这里写了一个练习项目,爬取哔哩哔哩网站上的番剧信息。
项目地址:https://github.com/xiaowenwen1995/AnimeSpider
总结
爬虫爬得好,牢饭吃到饱。
在写爬虫的时候还是要注意遵守robots协议。